
Not all servers are created equal, and the gap between standard and high-performance infrastructure matters far more than most business leaders realize. Understanding why high performance server decisions directly shape application speed, reliability, and competitive positioning is the kind of knowledge that separates reactive IT strategy from deliberate planning. This guide breaks down what high-performance servers actually are, how they work, the concrete benefits they deliver, and exactly when investing in them makes strategic sense for your organization.
Table of Contents
- Key takeaways
- Why high performance servers are more than fast hardware
- Benefits of high performance servers for your business
- Technical challenges that affect real-world server performance
- High performance server use cases where investment pays off
- My take on what IT leaders actually get wrong
- How Netcloud24 supports demanding business workloads
- FAQ
Key takeaways
| Point | Details |
|---|---|
| Parallel processing cuts runtime | HPC servers break workloads into parallel parts, reducing computation from years to days. |
| High availability is by design | Fast failover and recovery must be built into architecture from the start, not added later. |
| NUMA effects silently hurt performance | Remote memory access on multi-socket servers can cost 2x the latency of local access. |
| Use cases drive ROI | AI training, financial analytics, and enterprise databases see the clearest return on HPC investment. |
| Cloud integration extends value | Hybrid and multi-cloud HPC architectures add resilience and compliance flexibility. |
Why high performance servers are more than fast hardware
When most people think about server performance, they picture faster CPUs and more RAM. That mental model is incomplete. High-performance computing (HPC) servers are purpose-built systems that coordinate multiple processors, memory banks, and interconnects to tackle workloads that no single processor could handle in a reasonable timeframe.
The architecture centers on clusters: groups of individual servers called nodes that work together. HPC clusters solve complex problems by distributing tasks across nodes, with specialized software coordinating their activities and assembling results. Think of it less like a single engine and more like a pit crew where every role is optimized and synchronized.
Three hardware layers define what makes a server genuinely high-performance.
- Compute: Multi-socket CPUs, GPUs, and specialized accelerators handle the actual calculations. The latest generation processors, like AMD EPYC 8005 CPUs, deliver up to 40% higher integer performance compared to previous generations while improving performance per watt. That matters in dense, power-constrained environments.
- Networking: Low-latency interconnects like InfiniBand keep nodes talking to each other fast enough that parallelism actually pays off. High bandwidth, low latency networking can reduce training time for large AI models from years to weeks.
- Storage: NVMe enterprise-grade storage eliminates I/O bottlenecks that would otherwise negate raw compute gains.
The table below compares standard and HPC server capabilities at a glance.
| Feature | Standard server | HPC server |
|---|---|---|
| Workload type | Single-threaded business apps | Massively parallel scientific or AI workloads |
| Interconnect | Gigabit/10GbE Ethernet | InfiniBand or high-speed fabric |
| Scaling model | Vertical (add RAM/CPU) | Horizontal (add nodes) |
| Failover time | Minutes | Seconds or sub-second |
| Storage | SAS/SATA HDDs or basic SSDs | NVMe enterprise arrays |
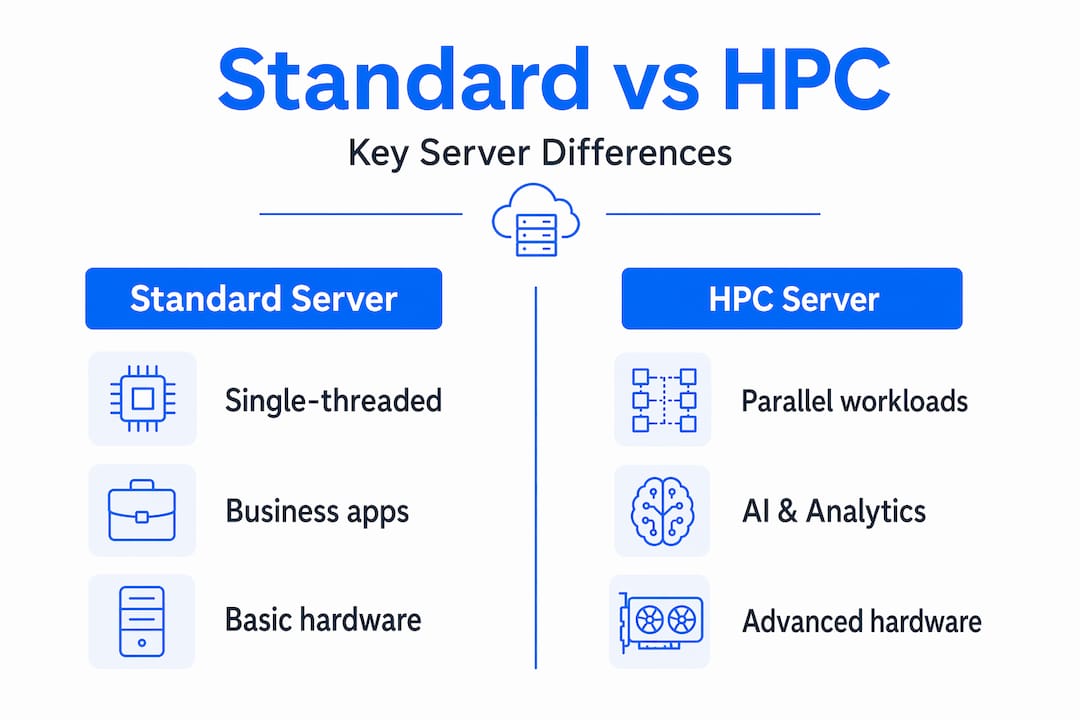
The distinction is not just technical. It defines what problems your organization can realistically take on.
Benefits of high performance servers for your business
Speed and reliability are the headline benefits, but the real advantages of high performance servers run deeper than raw throughput numbers.
Faster time to insight. Modern HPC systems perform quadrillions of calculations per second using parallel processing across thousands of nodes. For a financial services firm running risk models overnight, compressing that window from eight hours to forty minutes is not a convenience. It is a competitive edge.

Improved application uptime. In high-availability database architectures, Oracle Exadata recovers failures in under two seconds, compared to 30 seconds or more on conventional platforms, sustaining a 99.95% uptime SLA. For any application where downtime means lost revenue, that difference is enormous.
Scalability that matches demand. High-performance servers support cloud bursting, where you extend on-premises compute capacity into the cloud during peak loads and scale back when demand drops. This gives you enterprise-grade capacity without permanently paying for peak provisioning.
The specific business advantages of high performance servers worth prioritizing:
- Reduced time-to-result for AI model training, simulations, and analytics
- Higher application responsiveness for remote users accessing business-critical software
- Fewer unplanned outages through integrated redundancy and failover
- Ability to support emerging workloads like large language model inference or autonomous systems
- Compliance with data protection requirements through architectures designed for data locality
Pro Tip: When evaluating the benefits of high performance servers for your environment, prioritize workloads where latency or downtime directly affect revenue. That is where the ROI calculation becomes straightforward.
Multi-cloud deployments add another layer of resilience. Redis Enterprise clusters support multi-cloud architectures with automatic data distribution and failover, reducing the impact of cloud provider outages while also supporting data sovereignty compliance. That combination of performance and regulatory alignment matters deeply to businesses operating under GDPR.
Technical challenges that affect real-world server performance
Here is where a lot of IT decisions go wrong. Buying impressive hardware specs does not automatically deliver impressive performance. Several technical realities can quietly undermine what your investment should be delivering.
The most underappreciated of these is NUMA. Non-Uniform Memory Access describes what happens in multi-socket servers where each processor has faster access to its own local memory than to the memory attached to a neighboring socket. Remote memory access costs can be 2.1x that of local access, directly impacting latency and throughput. A server with two high-end sockets and 512GB of RAM can perform worse than expected if the workload has not been designed to respect NUMA boundaries.
"Memory locality matters more than thread count for performance on modern multi-socket servers. Partitioning data and ensuring threads access local NUMA node memory can significantly improve throughput." — Towards Dev
NUMA-aware software uses thread binding and first-touch memory allocation to keep processing and data on the same socket. Without that alignment, you are leaving measurable performance on the table. This is why hardware and software must be evaluated together, not independently.
The second challenge is failover architecture. Many organizations treat recovery time objectives (RTO) and recovery point objectives (RPO) as something to configure after deployment. That approach produces weak results. Oracle's Maximum Availability Architecture integrates high availability, data protection, and disaster recovery as core design principles, not optional configurations. Highly available systems built this way achieve automated failover in single-digit seconds without manual intervention.
Common pitfalls IT teams encounter in practice:
- Ignoring NUMA topology when deploying database or analytics workloads
- Treating failover as a manual process rather than an automated system feature
- Over-provisioning compute while under-provisioning networking and storage
- Deploying generic server images without tuning for specific workload characteristics
- Skipping memory locality testing under realistic production load
The pattern across all of these is the same. The hardware is capable. The configuration does not fully use it.
High performance server use cases where investment pays off
Understanding the high performance server importance in theory is one thing. Seeing where it delivers real results makes the investment case concrete.
The table below maps key use cases to the server characteristics that make them viable.
| Use case | Critical server attribute | Business outcome |
|---|---|---|
| AI/ML model training | GPU clusters, high-bandwidth interconnects | Faster model iteration, faster deployment |
| Financial risk modeling | Low-latency compute, fast storage | Overnight batch jobs reduced to minutes |
| Enterprise ERP and databases | High availability, fast failover | Continuous operations, minimal unplanned downtime |
| Scientific simulations | Massively parallel CPU/GPU nodes | Problems solved in hours instead of weeks |
| Secure remote work environments | Low-latency access, NVMe storage | Consistent performance for distributed teams |
| Autonomous systems development | Real-time processing, GPU acceleration | Safe iteration in simulation before deployment |
Remote work infrastructure deserves specific attention. As companies in Ireland and across Europe have moved toward distributed work models, high-performance Windows VPS hosting has become a practical way to deliver consistent, low-latency desktop and application experiences to remote users without maintaining physical hardware at every location.
For enterprise databases running ERP, CRM, or accounting software, the advantages of high performance servers translate directly into application responsiveness that staff and customers notice every day. A two-second page load versus a half-second response in a high-transaction environment adds up across hundreds of sessions daily.
The high performance server use cases that generate the clearest ROI share a common characteristic. They involve workloads where performance degradation either costs revenue, delays decisions, or creates compliance exposure. If your critical applications fall into any of those categories, the investment decision is not speculative.
My take on what IT leaders actually get wrong
I have watched organizations spend significant budgets on top-tier server hardware and then deploy it in ways that recover maybe 60% of the theoretical performance. The mistakes are almost never about the wrong hardware choice. They are almost always about the mismatch between how the hardware works and how the software uses it.
NUMA is the clearest example. I have seen multi-socket database servers where the team was proud of their hardware specs, but no one had profiled memory access patterns. When we ran NUMA-aware benchmarks, remote memory access was hammering latency on queries that should have been fast. The fix required software changes, not a hardware upgrade. The hardware was already capable.
My second observation: organizations that treat high availability as something to configure post-deployment consistently struggle with recovery times. The teams that build RTO and RPO targets into their architecture from day one, as actual design constraints, get the outcomes they need. It sounds obvious but the proportion of deployments where failover is tested rigorously before go-live is lower than it should be.
If I had to give one piece of advice for IT leaders evaluating why invest in high performance servers, it would be this: benchmark your actual workload, not a synthetic one. Vendor benchmarks use optimized configurations and purpose-built test suites. Your database, your ERP instance, your analytics pipeline behaves differently. Know your numbers before you commit.
Hybrid cloud integration is where I see the most upside being left on the table in 2026. Organizations that combine on-premises HPC for latency-sensitive workloads with cloud bursting for peak demand are getting the best of both without paying for either at full scale permanently. That flexibility is the enterprise IT scalability model that actually matches how business demand moves.
— Lukasz
How Netcloud24 supports demanding business workloads
The benefits and advantages of high performance servers described in this guide are exactly what Netcloud24 has built its hosting infrastructure around. For Irish businesses running ERP systems, accounting software, or any application where performance and uptime are non-negotiable, Netcloud24's enterprise-grade Windows VPS hosting delivers NVMe storage, high availability architecture, and automated failover in a pre-configured environment that is live within five minutes. The platform includes RDS licensing for multi-user access, VPN and firewall security, GDPR-compliant data handling, and flexible resources that scale with your business. If you are ready to stop accepting performance trade-offs and move your critical applications onto infrastructure that is built for them, Netcloud24 is the place to start.
FAQ
What makes a server high performance?
A high-performance server combines multi-core or multi-socket processors, high-bandwidth low-latency networking, NVMe storage, and software configured to exploit parallelism and memory locality. The architecture is designed to handle compute-intensive or high-throughput workloads that standard servers cannot process efficiently.
Why invest in high performance servers for business applications?
High-performance servers reduce downtime, cut processing time for analytics and AI workloads, and deliver consistent application responsiveness for staff and customers. For businesses where latency or outages carry direct revenue or compliance consequences, the investment has a clear financial case.
What are the biggest technical risks with high performance servers?
NUMA effects on multi-socket servers can reduce effective throughput by over 50% if software is not configured for memory locality. Inadequate failover design is the second major risk, with manual recovery processes creating unnecessary downtime even on otherwise capable hardware.
When should a business choose high performance servers over standard ones?
Choose high-performance infrastructure when your workloads involve large datasets, parallel processing requirements, AI or machine learning, or when application downtime directly impacts operations. Standard servers are adequate for low-traffic websites or basic file storage but fall short for enterprise databases and analytics platforms.
How does cloud integration affect high performance server strategy?
Multi-cloud and hybrid deployments extend the value of high-performance server investment by adding geographic redundancy, supporting data sovereignty compliance, and enabling cloud bursting for demand peaks. Automated failover across cloud providers keeps applications running even during provider-level outages.